Meta's AI Swarm Documents Hidden Code Knowledge Across 4,100+ Files
The Challenge: AI Without Context in Multi-Repository Pipelines
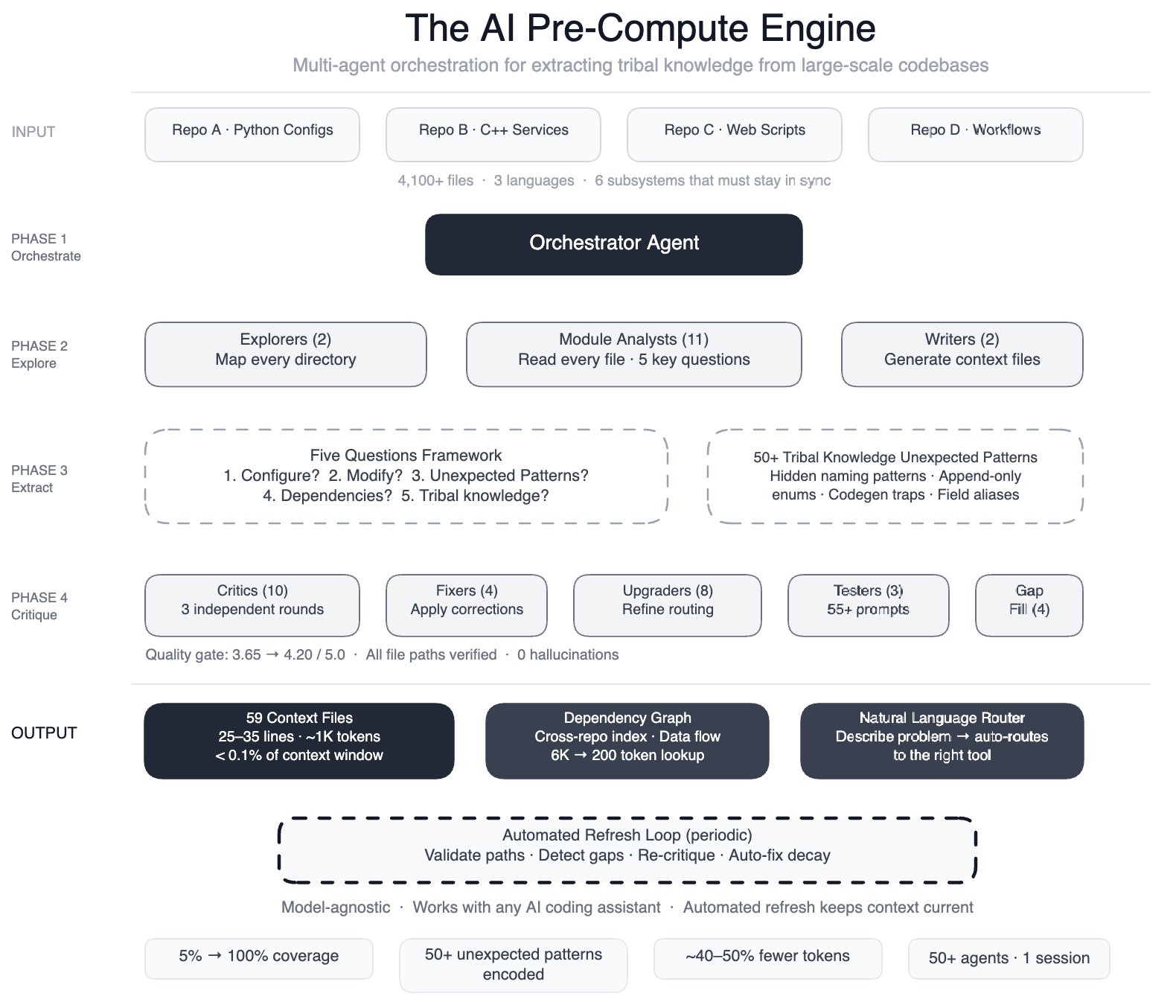
AI coding assistants are only as effective as their grasp of the codebase they work with. When Meta directed AI agents at one of its large-scale data processing pipelines—a sprawling system spanning four repositories, three programming languages, and over 4,100 files—the agents struggled. They failed to make useful edits quickly enough, often guessing, exploring, and guessing again, producing code that compiled but was subtly wrong.

This pipeline operates as config-as-code: Python configurations, C++ services, and Hack automation scripts collaborate across multiple repositories. A single data field onboarding process touches configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts—six subsystems that must remain perfectly synchronized. Without a map, the AI had no way to understand critical nuances, such as two configuration modes using different field names for the same operation (swapping them yields silent incorrect output) or dozens of deprecated enum values that must never be removed because serialization compatibility depends on them.
The Solution: A Pre-Compute Engine of 50+ Specialized Agents
To solve this, Meta built a pre-compute engine: a swarm of over 50 specialized AI agents that systematically read every file and produced 59 concise context files. These files encode tribal knowledge that previously existed only in engineers' minds. The result is a structured navigation guide for 100% of the code modules—up from just 5%—covering all 4,100+ files across three repositories. The system also documented more than 50 "non-obvious patterns," which are underlying design choices and relationships not immediately apparent from the code.
Importantly, this knowledge layer is model-agnostic, meaning it works with most leading AI models. Preliminary tests show a 40% reduction in AI agent tool calls per task, as agents no longer waste time exploring unfamiliar code.
How It Works: From Explorer Agents to Quality Critics
The process uses a large-context-window model and task orchestration to structure work in distinct phases:
- Explorer agents mapped the codebase, identifying file relationships and dependencies.
- Module analysts read every file and answered five key questions about its purpose, inputs, outputs, and connections.
- Writers generated 59 context files summarizing the findings.
- Critic passes ran three rounds of independent quality review, involving over 10 critic agents.
- Fixers applied corrections and refinements.
- Upgraders enhanced the routing layer.
- Prompt testers validated more than 55 queries across five different user personas.
- Gap-fillers covered remaining directories.
- Final critics ran integration tests to ensure everything was consistent.
This orchestrated swarm—50+ specialized tasks in a single session—transformed the AI from a blind explorer into a guided assistant.
Results: Structured Navigation for All Modules, 40% Fewer Tool Calls
The system now provides AI agents with structured navigation guides for every code module. Initially, only 5% of modules had such documentation; now 100% are covered. Engineers no longer need to manually pass institutional knowledge to the AI; the context files encode all the tribal knowledge. With this map, agents make far fewer exploratory calls—preliminary tests indicate a 40% reduction in tool calls per task. This means faster, more accurate edits and less wasted computation.
Self-Maintaining System: Automated Validation and Updates
Perhaps most impressive, the system maintains itself. Automated jobs run every few weeks to validate file paths, detect coverage gaps, re-run quality critics, and auto-fix stale references. The AI is not just a consumer of this infrastructure; it is the engine that runs it. This ensures the knowledge layer stays current as the codebase evolves, without requiring manual intervention.
By systematically documenting tribal knowledge and making it accessible to AI agents, Meta has turned a chaotic pipeline into a well-mapped territory. The approach is model-agnostic, scalable, and self-sustaining—a blueprint for other organizations grappling with complex, multi-repository systems.