Unlocking AI Performance: How Meta’s KernelEvolve Agent Streamlines Infrastructure Optimization
Imagine running billions of AI-powered services daily—recommendations, generative assistants, ads ranking—on a sprawling mix of NVIDIA GPUs, AMD GPUs, Meta’s custom MTIA chips, and CPUs. The catch? Each piece of hardware needs finely tuned software code, called kernels, to translate high-level model instructions into efficient, chip-specific operations. Hand-tuning these kernels for every new chip generation and model architecture is a nightmare that doesn’t scale. That’s why Meta built KernelEvolve, an agentic system that automates kernel optimization as a search problem. This article dives into the key questions about how KernelEvolve works, what it achieves, and why it matters for the future of AI infrastructure.
What problem does KernelEvolve solve at Meta?
Meta operates a vast fleet of heterogeneous hardware—NVIDIA GPUs, AMD GPUs, custom MTIA silicon, and CPUs—to run AI models ranging from ads ranking to generative AI. For each hardware type and model architecture, engineers must write and optimize specialized kernels (low-level code that executes math operations like matrix multiplications). Standard vendor libraries cover common operators, but production workloads require many custom operators that aren’t available off the shelf. As the number of models and hardware generations multiplies, manual tuning by kernel experts becomes impossible. KernelEvolve tackles this bottleneck by treating kernel optimization as an automated search: it generates, evaluates, and iterates on candidate kernels far faster than humans, compressing weeks of expert work into hours.
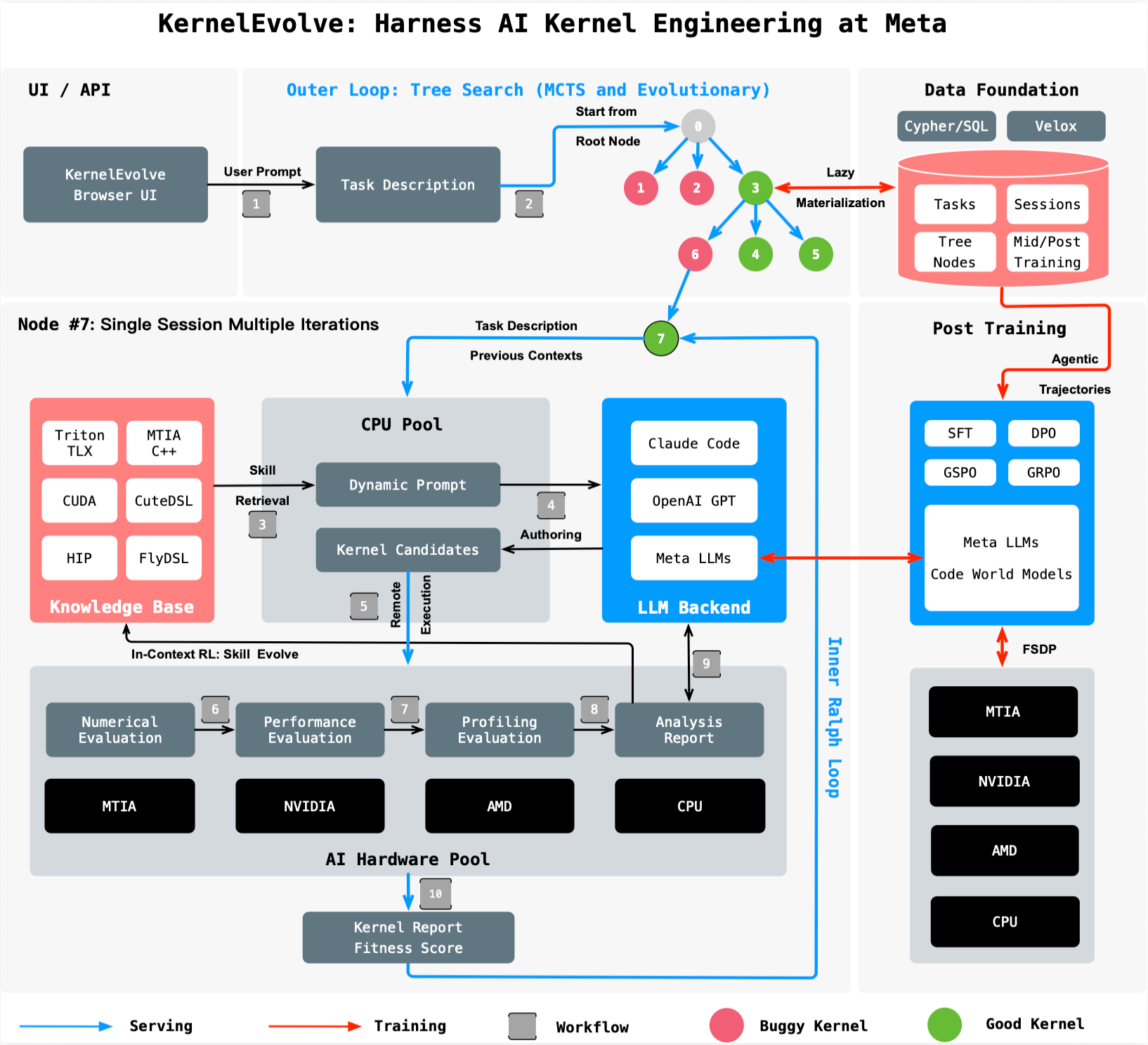
How does KernelEvolve work as an agentic system?
KernelEvolve frames kernel optimization as a search problem with an agentic loop. A purpose-built job harness evaluates each candidate kernel’s performance, feeds diagnostics back to a large language model (LLM), and drives a continuous search over hundreds of alternatives. The LLM proposes new kernel code based on previous results, and the harness tests them on real hardware. This cycle repeats, automatically refining the kernel until it meets performance targets or surpasses human-written versions. Unlike static autotuning, KernelEvolve’s agentic nature lets it explore creative solutions, such as novel tiling strategies or memory-access patterns, that human experts might miss. The result is a system that not only matches but often exceeds human expertise in speed and quality.
What hardware platforms does KernelEvolve support?
KernelEvolve is designed for heterogeneous hardware across Meta’s infrastructure. It supports public platforms like NVIDIA GPUs and AMD GPUs, as well as proprietary silicon such as Meta’s custom MTIA chips and CPUs. This broad compatibility is critical because Meta’s AI models run on a mix of devices depending on cost, power, and performance requirements. The system generates kernels in multiple languages: high-level domain-specific languages (DSLs) like Triton, Cute DSL, and FlyDSL, plus low-level languages including CUDA (for NVIDIA), HIP (for AMD), and MTIA C++ (for custom chips). This flexibility ensures that no matter the accelerator, KernelEvolve can produce optimized code without human rewrites.
What performance gains has KernelEvolve achieved?
KernelEvolve has delivered significant throughput improvements on real Meta models. For the Andromeda ads model running on NVIDIA GPUs, it achieved over 60% inference throughput improvement. On Meta’s custom MTIA silicon chips, it improved training throughput for an ads model by more than 25%. These gains come from exploring hundreds of kernel variants, each profiled and refined, to identify configurations that outperform hand-tuned kernels. Such efficiency boosts directly translate to lower latency for users, more models served per hardware dollar, and reduced energy consumption. The system’s ability to generalize across different operators—not just GEMMs and convolutions—makes these gains possible for the many custom operators typical in production workloads.
How does KernelEvolve compare to human expert tuning?
Traditional kernel tuning by human experts is a labor-intensive process: profiling, analyzing bottlenecks, writing optimized code, debugging across hardware variants, and repeating. A single kernel can take weeks of expert time. KernelEvolve compresses this into hours of automated search and evaluation. Moreover, it often exceeds human performance because the LLM-driven exploration can test unconventional strategies that even seasoned engineers might not consider. The system also scales effortlessly: while a team of kernel experts is limited by headcount, KernelEvolve can run multiple optimization jobs in parallel on different hardware backends. This frees engineers to focus on higher-level architecture and model design rather than low-level performance tuning.
Is KernelEvolve only for Ads models, or can it be used elsewhere?
Although KernelEvolve was developed for Meta’s Ads Ranking use case, it is designed to be broadly applicable. The system optimizes kernels for any AI model that runs on the supported hardware—including recommendation systems, computer vision, natural language processing, and generative AI. Its agentic search methodology and support for multiple DSLs and low-level languages make it easy to adapt to new model architectures. The underlying principle—automated, iterative kernel optimization driven by LLM feedback—works for any operator, from simple element-wise operations to complex attention mechanisms. Meta has already applied it beyond ads, and the research paper (presented at ISCA 2026) describes its generalizability.
Where can I learn more about KernelEvolve?
Detailed technical information is available in the paper titled “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta,” which will be presented at the 53rd International Symposium on Computer Architecture (ISCA 2026). The paper covers the system architecture, experimental results on multiple hardware platforms, and comparisons with human-written kernels. For practical insights, Meta’s Ranking Engineer Agent blog series (this post is the second in the series) explores how autonomous AI capabilities accelerate innovation. The first post introduced the agent’s ML exploration capability for designing and executing ranking model experiments.